ControlNet 1.1考察 (Stable Diffusion)
はじめに
ControlNet 1.1で、考察してみました。
- Lineart
- Shuffle
- Inpaint
- Tile
- Depth
- Normal
- Canny
- Scribble
- Soft Edge
- MLSD
- Segmentation
- Openpose
Lineart
入力画像を一旦線画に変換し、それを元に画像生成を行うモデル
| 入力 | lineart | 生成 |
 |  |  |
lineart_realistic
Shuffle
入力画像をシャッフルして再構成するモデル。
今回は、呪文に「1boy」で生成してみました。
| 入力 | Shuffle | 生成 |
|  |  |
Shuffle
Inpaint
画像の一部を修正するモデル。
顔のみ塗りつぶしました。
| 入力 | Inpaint | 生成 |
|  |  |
Inpaint
Tile
高解像度の画像を生成する際にディテールをうまく補完するためのモデル。
| 入力 | Tile(512px) | 生成(900px) |
|  |  |
Tile
Depth
入力画像の深度情報を元に画像生成を行うモデル
| 入力 | Depth | 生成 |
|  |  |
Depth_leres
Normal
入力画像の凸凹情報を元に画像生成を行うモデル
| 入力 | Normal | 生成 |
|  |  |
normal_bae
Canny
入力画像の輪郭を抽出して画像生成を行うモデル
| 入力 | Canny | 生成 |
|  |  |
Canny
Scribble
落書きを元に画像生成を行うモデル
| 入力 | Scribble | 生成 |
 |  |  |
scribble_hed
Soft Edge
やわらかい輪郭線を生成し、それを元に画像生成を行うモデル
| 入力 | softedge | 生成 |
|  |  |
softedge_hed
MLSD
入力画像の直線を抽出して画像生成を行うモデル
| 入力 | mlsd | 生成 |
 |  |  |
mlsd
Segmentation
入力画像を物体ごとに識別・分割し、それを元に画像生成を行うモデル
| 入力 | Segmentation | 生成 |
 |  |  |
seg_ofade20k
Openpose
被写体のポーズを認識し、棒人間を生成してそれを元に画像生成を行うモデル
| 入力 | Openpose | 生成 |
| 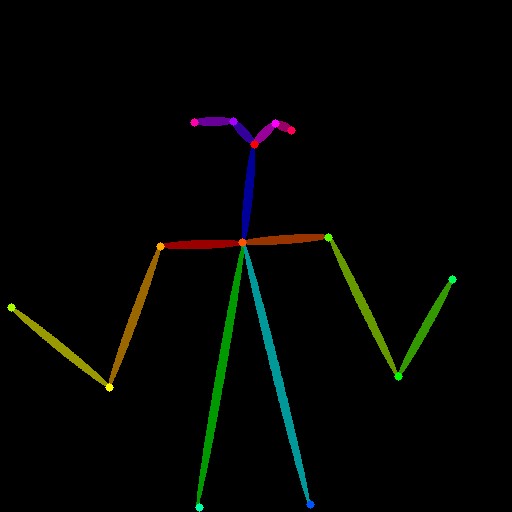 |  |
Openpose
考察
動画を制作する際などに、大活躍しそうです。
一部修正する際にも、使用できそうです。
おすすめサイト
「ControlNet 1.1」の新機能まとめ!新しいモデルや改善点を紹介【Stable Diffusion】
「ControlNet 1.1」の新機能まとめ!新しいモデルや改善点を紹介【Stable Diffusion】 | くろくまそふと
今回もStable DiffusionのControlNetに関する話題でControlNet 1.1の新機能を一通りまとめてご紹介するという内容になっています。ControlNetは生成する画像のポーズ指定…